本小站背后是某云的虚拟主机 + Nginx + WordPress,操作系统是Ubuntu Server。国庆假期之后上来访问发现web服务挂了,登录到服务器上发现是Nginx进程没了,国庆假期期间一直没有什么操作,Nginx自己挂了,觉得有点不可思议,于是简单调查了下原因,原来是Ubuntu本身的原因导致,具体调查步骤如下。
-
首先查看Nginx进程,
ps aux | grep nginx,发现Nginx进程没了 -
检查Nginx本身的错误日志,默认路径是/var/log/nginx,看到从10月3日起,就没有访问日志了,推测应该是10月2日就挂了。
-
详细查看10月2日的error日志,发现都是一些访问错误的请求,并无Nginx进程相关的错误,也就是说应该不是请求错误导致nginx挂掉,应该是有什么东西直接操作了Nginx的进程。
-
首先怀疑,有人黑进来,检查了history、远程登录记录等,并未发现有可疑登录和命令执行。再加上本小站,本身就是一个日常记录的技术博客,被黑的价值也比较低,所以可能性不高。
-
继续查Nginx的记录,本博客的Nginx是使用Ubuntu systemd来管理的,来看一下Nginx的详细启停记录,
journalctl -xeu nginx.service
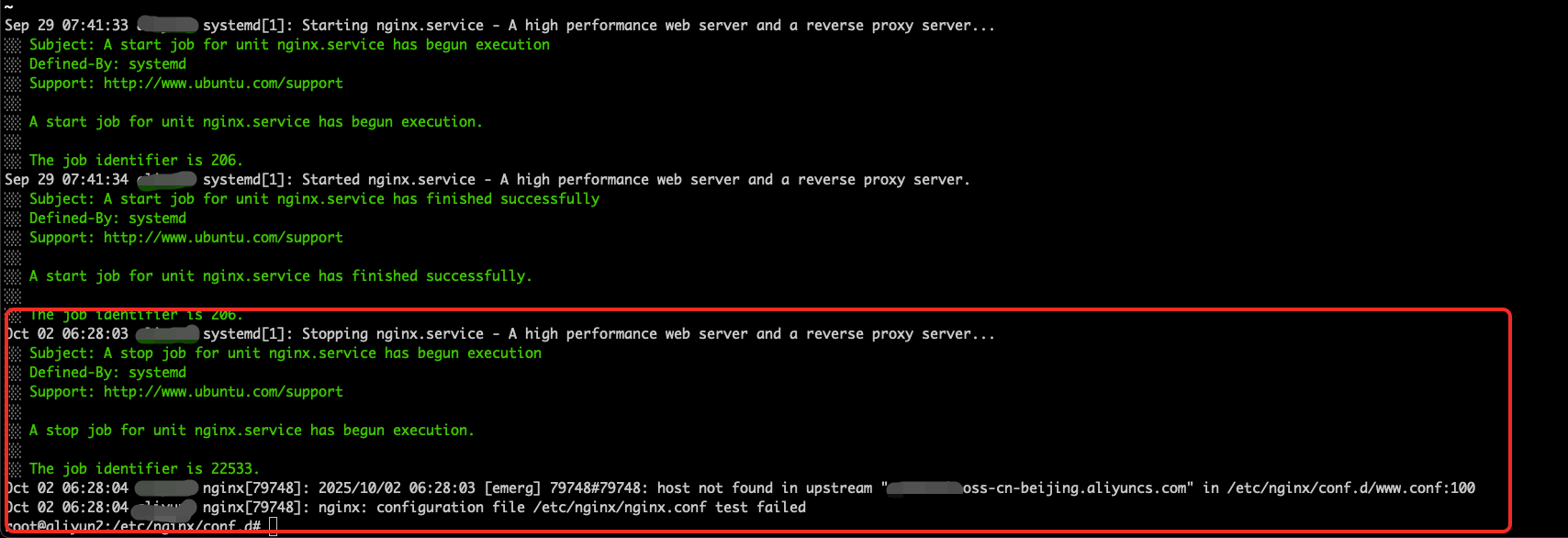
上面日志,可以看到是10月2日,6点28分,Nginx被操作系统重启,但是启动的时候,无法解析配置的upstream的域名,导致配置文件解析失败,进而引起Nginx进程启动失败。 -
继续查看该时间点的详细系统日志,
journalctl --since "2025-10-02 06:27" --until "2025-10-02 06:30"
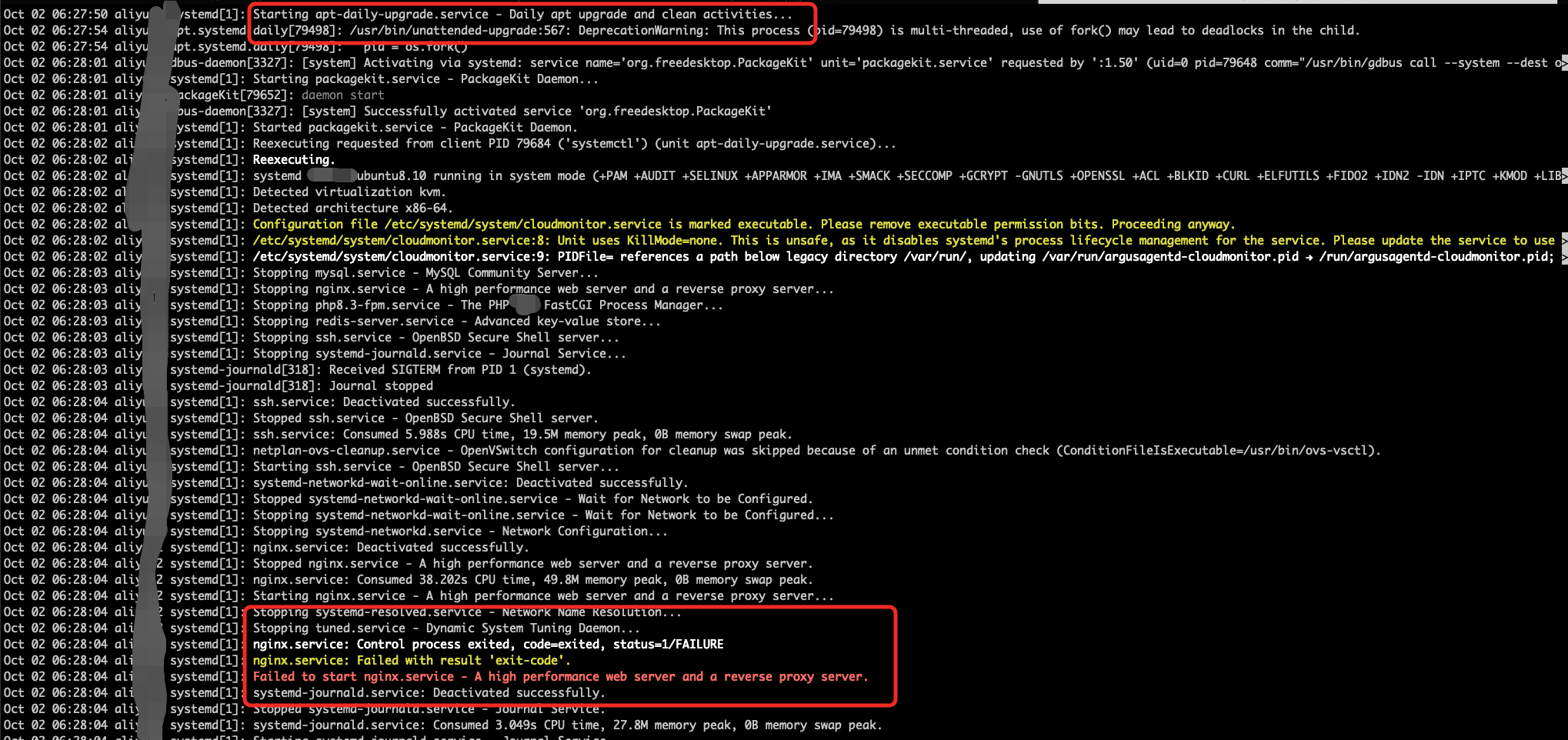
从系统日志中可以看到是Ubuntu操作系统本身的apt-daily-upgrade.service - Daily apt upgrade and clean activities...在上午6点27分启动,执行之后,重启了mysql、php、Nginx、ssh等进程,然后Nginx启动失败了;到这里,追查到了Nginx被重启的源头。 -
为何nginx会重启失败?
看日志是因为配置的阿里云oss的一个upstream引起,猜测可能是因为nginx启动的时候,阿里云虚拟主机的dns存在延时或者故障,导致upstream中的域名没有解析成功,进而nginx判断配置文件不合法,故拒绝启动。location / { proxy_pass https://yeetrack.oss-cn-beijing.aliyuncs.com; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } -
为何Ubuntu会自动进行系统更新?
apt-daily-upgrade.service是Ubuntu系统(包括desktop和server)自带的系统更新服务,默认情况下每天会在每天6点和18点进行启动,来保证系统的一些关键更新会被及时安装。 -
为何Ubuntu操作系统,会做这种有些“不合理”的设计?
这可能是跟Ubuntu自身的定位有关,Ubuntu的定位是小型服务器、小型云虚拟机、开发机或者linux桌面系统,这类场景对系统稳定性要求不是特别高,所以厂商为了保证系统的安全性,一些安全漏洞等关键更新能被及时安装。
但对于大型企业的生产环境来说,这种自动更新策略,有可能会引发严重的问题,尤其是一些比较底层的软件更新,可能会导致软件版本不兼容、服务中断、主从切换、流量雪崩等,所以Ubuntu server并不是大型企业生产环境服务器的首选,一般都是选择redhat、suse、centos等更稳定的系统。 -
手工关闭Ubuntu的自动更新
专业的运维,在使用Ubuntu作为生产环境之前,应该会进行一些初始化的配置修改,来让系统更稳定,如关闭自动更新。systemctl disable --now apt-daily.timer systemctl disable --now apt-daily-upgrade.timer systemctl mask apt-daily.service systemctl mask apt-daily-upgrade.service
原创文章,转载请注明: 转载自空空博客
本文链接地址: 记一次Nginx进程挂掉的原因调查
文章的脚注信息由WordPress的wp-posturl插件自动生成

近期评论