工厂产线采购了某供应商的一套生产调度系统,其中一块服务的技术栈是互联网常见的K8S+springboot,最近该K8S集群内的某个服务的pod在访问某域名,偶尔会有超时情况,概率也不大,一两周出现几分钟,每次出现超时会让工厂产线停工,对此问题进行了跟踪调查,发现了一些问题,并学到一些知识,记录如下。
一、背景知识
- jvm本身会对DNS的解析记录进行缓存,缓存时间一般为30秒,该超时时间支持手动设置。
- DNS服务器分主从,从DNS服务器会定时同步主DNS服务器的记录,缓存到本地。
- Linux操作系统(如Ubuntu等),一般默认会安装DNS解析的程序,如systemd-resolved、nscd等,这些服务也会对DNS的记录进行缓存,缓存的时间一般为域名的TTL时间。
二、服务架构图
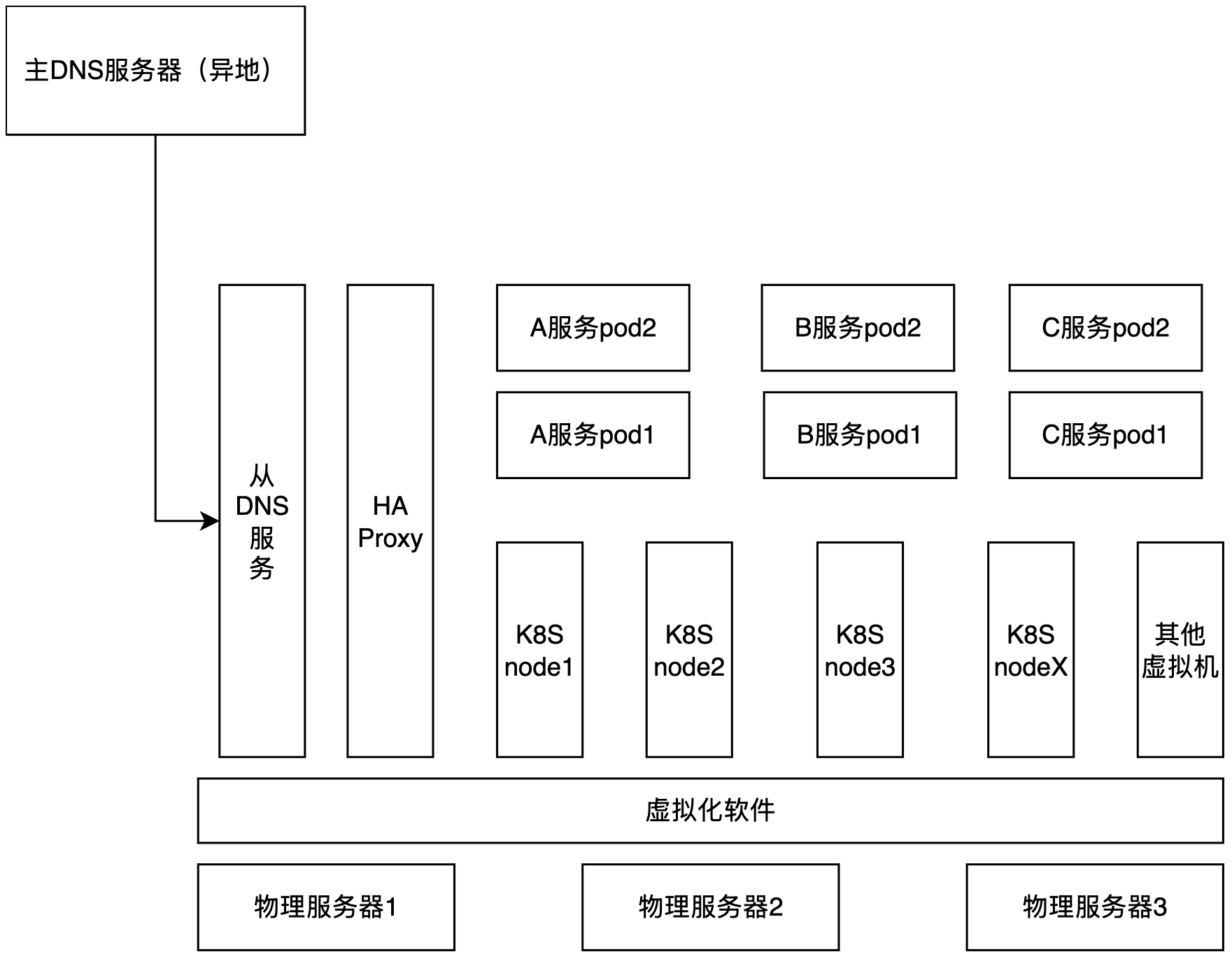
- 主DNS服务器在异地,并且跨城,走的是公网传输。
- K8S集群内的pod相互访问,没有走svc,而是通过haproxy代理,然后走Ingress网关。(这一点真的很奇怪,为何要绕一大圈)。
三、调查过程
- 首先怀疑是从DNS服务器不稳定,域名解析出现超时。在几台K8S node虚拟机上。于是在几台node虚拟机上,启动了脚本一直ping 超时的域名,执行了几十万次也没有出现超时的情况。这里其实并不能证明DNS服务器正常,因为node机器上的Linux操作系统,一般都会安装DNS缓存程序,大部分DNS请求都命中操作系统的DNS缓存了。
- 既然是pod访问DNS异常,就从pod查起,首先查看pod的yaml配置文件,DNS策略是如何配置的。从rancher上看到是
dnsPolicy: ClusterFirst,该策略是pod默认的DNS策略,会首先从集群内部查,如果获取不到再查上层的DNS服务器。 -
查看pod中的DNS配置,
cat /etc/resolv.conf# cat /etc/resolv.conf nameserver 169.254.25.10 search prod.svc.cluster.local svc.cluster.local cluster.local options ndots:5可以看到设置的是默认的K8S集群默认的DNS地址,也就是每个node上的nodelocaldns服务。
-
查看nodelocaldns的配置,在K8S的node上执行
kubectl -n kube-system get configmap nodelocaldns -o yamlapiVersion: v1 data: Corefile: | cluster.local:53 { errors cache { success 9984 30 denial 9984 5 } reload loop bind 169.254.25.10 forward . 10.233.0.3 { force_tcp } prometheus :9253 health 169.254.25.10:9254 } in-addr.arpa:53 { errors cache 30 reload loop bind 169.254.25.10 forward . 10.233.0.3 { force_tcp } prometheus :9253 } ip6.arpa:53 { errors cache 30 reload loop bind 169.254.25.10 forward . 10.233.0.3 { force_tcp } prometheus :9253 } .:53 { errors cache 30 reload loop bind 169.254.25.10 forward . /etc/resolv.conf prometheus :9253 } kind: ConfigMap可以看到一些K8S集群内部的域名,会转发到集群的coredns服务上(10.233.0.3),其他域名还是都会落入nodelocaldns这个pod的/etc/resolv.conf文件中,并且有30秒的缓存。
-
检查nodelocaldns的配置文件,
cat /etc/resolv.confcat resolv.conf nameserver 1.2.3.4看到里面就是工厂机房里常用的DNS从服务器。
- 走到这一步基本把这套系统的业务pod内域名解析的链路查清楚了,假设是A服务的pod1内的java代码要访问B服务(假设域名是test.yeetrack.com),A服务的pod中的jvm进程访问test.yeetrack.com,
①jvm首先查看自己进程内的DNS缓存记录(30秒超时),如果命中了,直接返回;
②如果没命中,jvm会调用函数请求pod内的操作系统来尝试解析,pod本质上是个精简版的Linux,一般不会安装systemd-resolved类似的DNS缓存程序,所以直接回去查自己的hosts文件,如果命中了,就直接返回。
③pod内的hosts没有命中,就去查/etc/resolv.conf中配置的DNS服务器,这里指向的是同一个node中的nodelocaldns的地址(169.254.25.10)。
④nodelocaldns一般会检查自己pod内的hosts文件,命中了就返回,没命中的话,基于自己的配置进行转发。
⑤最终在nodelocaldns pod里的/etc/resolv.conf中查到了DNS服务器,然后向其发送解析test.yeetrack.com的请求,DNS服务器应答。 - 但是从DNS服务器是相同机房内部的,是跟K8S node处于一个虚拟化环境中的,按理不应该出现网络访问问题。
- 再往上查,从DNS服务器的配置是从异地的主DNS服务器同步而来,如果从DNS服务器缓存到期,这时候公网链路又不稳定,则可能会出现从DNS服务器解析域名超时的情况。
四、解决方案
既然是K8S相同集群内的pod之间相互访问,当然是首先使用svc的方式直接访问,再经过域名解析一遍,太不合理,但由于是供应商的开发、维护的系统,无法对其改造;决定使用配置hosts的方法。
- 首先想到的是在所有的node上配置hosts,但没有生效;原因是K8S集群内pod中的解析,不会读取node机器上的文件,除非将虚拟机的hosts映射到容器里。
-
后来想到的是在coredns配置文件中把hosts加上,如下:
kubectl -n kube-system get configmap coredns -o yaml apiVersion: v1 data: Corefile: | .:53 { errors health { lameduck 5s } ready hosts { XX.XX.XX.XX test.yeetrack.com fallthrough } kubernetes cluster.local in-addr.arpa ip6.arpa { pods insecure fallthrough in-addr.arpa ip6.arpa ttl 30 } prometheus :9153 forward . /etc/resolv.conf { max_concurrent 1000 } cache 30 loop reload loadbalance } kind: ConfigMap - 然后再nodelocaldns的配置文件中,将此域名的解析转到coredns中。
test.yeetrack.com:53 {
bind 169.254.25.10
forward . 10.233.0.3 {
force_tcp
}
}
至此问题解决完毕。
五、几个观点
随便说说自己的几个想法:
- 互联网行业中的一些新技术、新框架,确实设计的非常巧妙,但是在一些传统行业、尤其中小型的公司,确实也会遇到一些问题,比如运维成本,生产关系确实要适配生产力,强行升级生产工具,可能会适得其反。
- 近些年,中国的汽车制造业进步很大,尤其一些新势力车企,在自动驾驶、智能座舱领域取得很大进展。汽车领域的发展,吸引了一大波高端自动驾驶、互联网从业者进入主机厂,这些人进入偏传统的主机厂后会和之前的汽车员工价值观、做事方法产生较大冲突;如何平衡这种关系,如何让两者协同发展,是车企领导者应该考虑的事情。
- 一些传统行业从业者(无论年龄大小),思维和技术栈,已经严重落后于时代了,新兴行业的人在与其协同工作时,会产生强烈的不适感;感觉像从智能手机时代,切回了摩托罗拉、诺基亚时代;很多公司的各种系统、平台、产品等均为供应商提供,公司仅负责集成,并不掌控核心技术。技术在更新迭代,对人、对公司、对行业都是这样。如果一家公司或者一个人没有核心竞争力或者壁垒,那可能就会被下一次技术更新所革命。
- 新兴行业的人,容易头脑过热,认为随便就能推翻整个行业,来次彻底的革命,就像之前中国产业互联网狂奔的二十年一样。其实,在工业领域,尤其一些底层精密的工业制造、工业软件、芯片等,都需要长期的投入才可能有产出,这些行业都需要静下心来慢慢积累。
原创文章,转载请注明: 转载自空空博客
本文链接地址: 记一次K8S集群内pod 偶现DNS超时问题解决
文章的脚注信息由WordPress的wp-posturl插件自动生成

近期评论